Sift 是数字信任和安全领域的领导者之一,其利用机器学习提供欺诈检测服务,已帮助500强的企业在不冒风险的前提下开启新的收入来源。通过基于机器学习的领先技术、专业知识和超过700亿个月度事件的全球数据网络,Sift 可以动态地预防多种滥用类别的欺诈行为。
Sift 的平台提供了一个直观的用户界面,让客户可以配置工作流程,自动化欺诈检测,满足高度关键的业务操作,如阻止可疑订单、对交易应用额外的摩擦(例如请求 MFA)或处理成功的交易。客户可以在 Sift 的用户界面中构建和管理他们的业务逻辑,使用工作流程自动化决策,并继续简化手动审核。Sift 的客户每天通过这些工作流程处理数千万个事件。
以下是 Sift 用户界面的示例以及工作流程如何使客户对用户事件(例如新建订单)进行基于风险的决策的示例。在下面的示例中,工作流程逻辑评估了传入请求的付款滥用分数,然后根据严重程度进行重定向。例如,在图像底部显示的路线3中,如果此类分数大于50,则触发基于电子邮件的双因素身份验证以验证传入请求,如果大于90,则将其标记为欺诈请求并进行阻止。
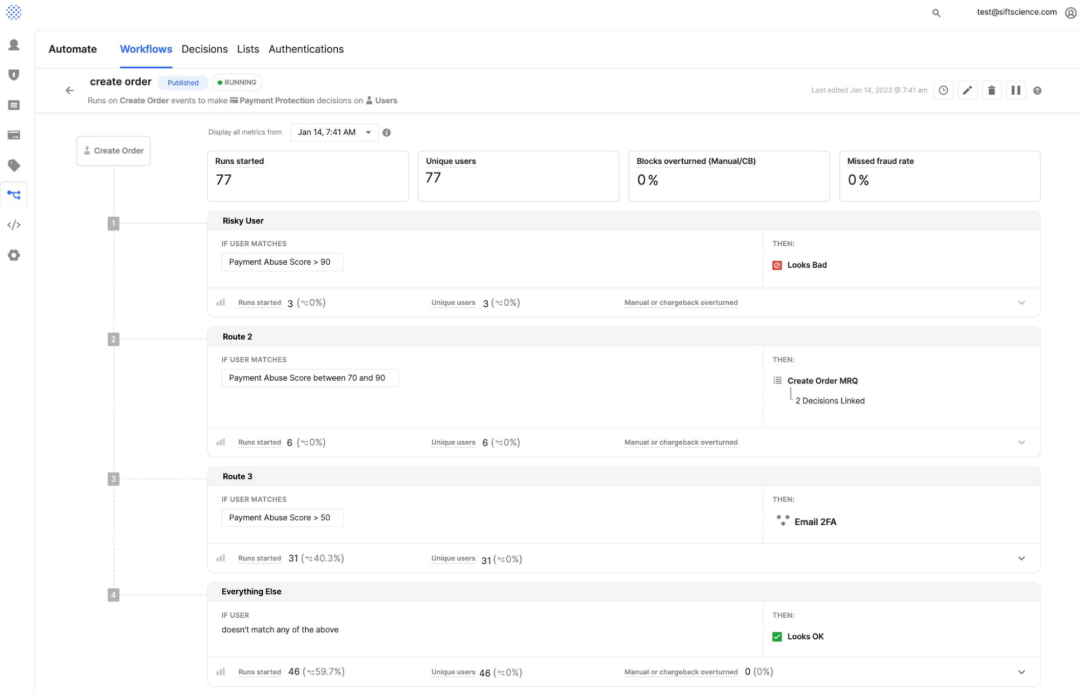
当对现有工作流程进行更改时,客户希望能够确信这些更改将对其核心 KPI(用户侮辱率、欺诈成本、月活跃用户、客户生命周期价值等)产生积极影响。将具有负面影响的工作流程路线投入生产可能会降低投资回报率,并可能拒绝有效的请求或非欺诈客户,这必须尽一切可能避免。
由 BigQuery 提供支持的工作流回测
由BigQuery提供支持的工作流回测架构通过使客户能够:
在正在运行的工作流中测试路由的更改(如上图所示)
自助服务并运行“假设”实验,无需通过 SiftUI 代码
使欺诈分析师能够在将工作流发布到生产环境之前评估路由的性能
以下是发出工作流请求时使用的完全托管和无服务器 Google Cloud 构建块的高级流程图:
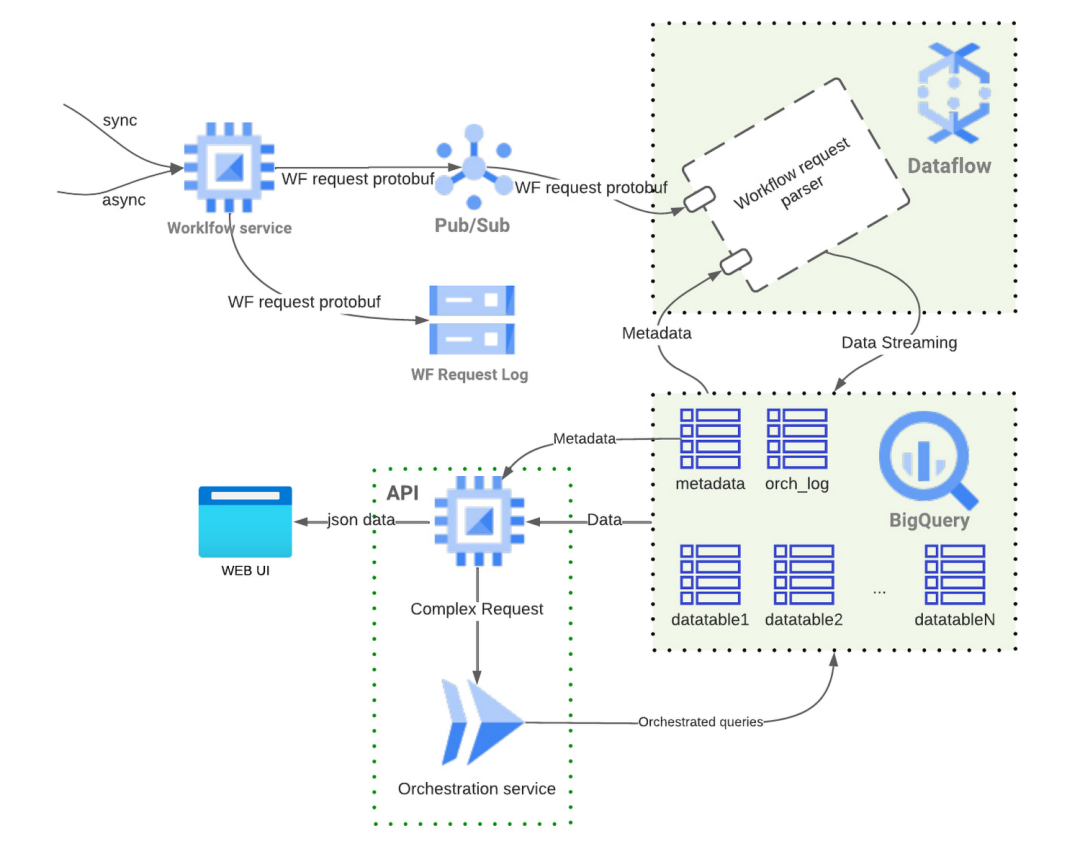
每当工作流服务接收到请求时,它都会将包含整个工作流请求的消息推送到 Cloud Pub/Sub 主题中。Dataflow 作业获取消息并通过解析器(工作流请求解析器)对其进行处理,该解析器从消息中提取所有可用字段。此过程使 Sift 能够将复杂的工作流请求转换为扁平化的、类似电子表格的结构,非常方便以后使用。之后,Dataflow 作业在 BigQuery(通过 Storage WriteAPI)中创建记录,遵循与模式无关的设计。
回测流程的编排
从概念上讲,回测被实现为动态生成的 SQL 查询。为了处理单个回测调用,Sift 需要运行三个或更多相互依赖的查询,并且应该以严格定义的顺序作为逻辑工作单元进行处理。Sift 控制台用于执行回测异步 API 调用。编排服务是一个基于 Spring Cloud 的简单 Web 应用程序,它公开了一个接受 JSON 格式请求的端点。每个请求都包括所有回测查询以及所有相关的查询参数和预先生成的 JobID。它解析请求并以正确的顺序执行针对 BigQuery 的所有查询。对于每一个步骤,它都会在日志表中创建一个状态记录,该日志表 API 查询有关数据准备状态的上下文。该过程可以在下一张图中描述:
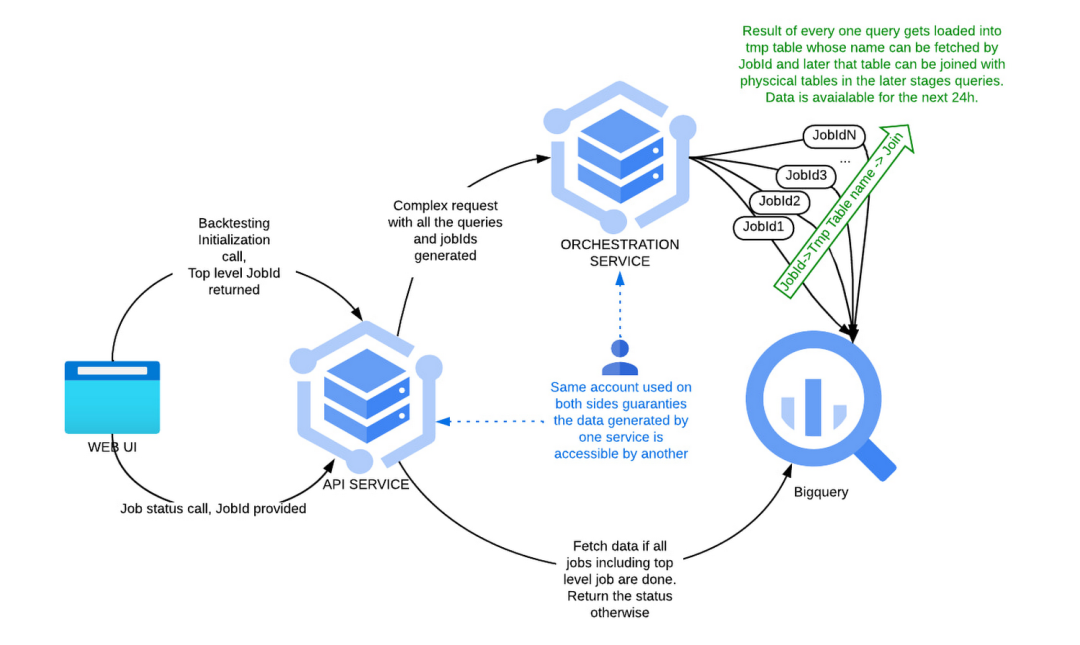
BigQuery的扩展能力和路径
每个工作流请求可能包含数以万计的列/字段,客户可以决定将其用于任何回测请求。表大小以 TB 为单位,每个表有数十亿条记录。此外,通常在测试新工作流之前添加或删除属性,因此需要一个与模式无关的设计,允许:
引入新特性,无需修改表的结构
通过修改元数据与模式以声明方式实现的更改
深度定制和可扩展性允许为使用许多自定义字段的客户提供超过一万种相同数据类型的功能

如上面的模式所示,数据被分组到按数据类型排列的表中,而不是工作流特定的布局。连接数据是通过使用关联元数据表来完成的,在传统数据仓库设计的上下文中,它可以被认为是(事实表)链接到多个数据类型表(维度表)。
数据量很大,模式经常变化,这使得索引工作劳动密集型且不太适用。在评估初始工作流架构期间,Sift 对具有大聚合的深度嵌套查询进行了全面测试,以确定最合适的模式设计,从而实现性能和灵活性。数据的列存储格式非常符合这一想法,因为它最大限度地减少了将数据加载到内存和通过复杂的动态查询进行进一步操作所需的 IO。在最终确定设计之前,Sift 进行了广泛的基准测试,针对多个数据仓库解决方案管理的可比数据量运行逻辑相似的查询,并对BQ驱动的解决方案进行基准测试。结论是BQs Dremel Engine 和集群级文件系统(Colossus)提供了其用例中性能最好且可扩展的架构。
使用BigQuery进行基准测试
在几次负载测试和处理一组具有大量数据和吞吐量的“类似生产”用例的过程中,团队对单个回测请求达到了令人满意的平均响应时间约为60秒,对复杂请求的最大响应时间接近2分钟。负载测试还有助于估计为预期工作负载提供足够的计算资源所需的 BQ 插槽数量。以下是初始 Jeter 测试报告的示例(配置:随机选择的 clientId/workflow confiId/routeId):
回测周期:45d
BQ计算资源:3000 BQ插槽
计划工作量达到:每分钟30个请求
测试时长:30分钟

此外,该团队还开始试验“BigQuery Slot Estimator”功能,允许:
工作流特定项目的插槽容量和利用率数据的可视化
识别使用最多时隙时的峰值利用率周期
探索作业延迟百分比(P90、P95)以了解与工作流回测序列相关的查询性能
随着时间的推移,增加或减少插槽如何影响性能的假设建模。
根据历史使用模式评估自动生成的成本建议
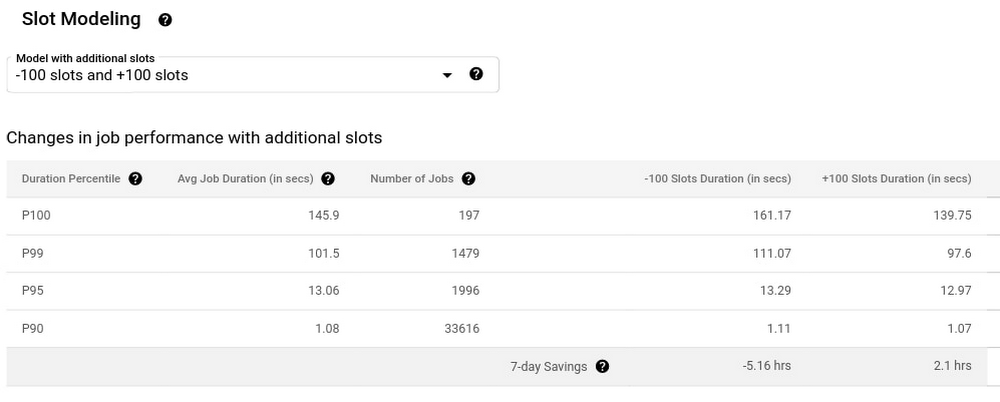
以下是利用 BQ 的插槽估算器来模拟不同容量水平下性能可能会如何变化的示例,模拟为当前容量的-100和+100插槽。
谷歌的数据云为构建数据驱动的应用程序提供了一个完整的平台,如Sift开发的工作流回测解决方案。简化的数据摄取、处理和存储到强大的分析、人工智能、机器学习和数据共享功能与开放、安全和可持续的谷歌云平台集成在一起。凭借多样化的合作伙伴生态系统、开源工具和API,谷歌云可以为科技公司提供服务下一代客户所需的可移植性和差异化。
———
WebEye是中国大陆地区首家获得 Google Cloud MSP 资质的合作伙伴。WebEye致力于用创新的技术向中国企业提供数字化效率创新服务,实现数字化赋能。我们不断帮助客户打造新的运营与协作方式,打造新的竞争优势,构建资源高效链接,共创价值生长空间。
WebEye整合全球资源,打造全球数字化营销体系,为企业提供营销增长服务、营销增长引擎以及企业上云三大板块业务,涵盖数字营销、数字创意、游戏发行、流量变现、程序化广告、数据洞察、云计算等一站式全链条增长产品矩阵,是中国互联网出海领军企业。